LIKE…a bo$$ !
On entend souvent dire qu’utiliser l’opérateur arithmétique = ou faire un LIKE sur une chaîne de caractères dans MySQL revient au même. Oui et non…Oui car au final les tuples qui « remontent » de nos tables sont les mêmes mais non car en coulisses l’impact sur le temps d’exécution n’est pas forcément le même.
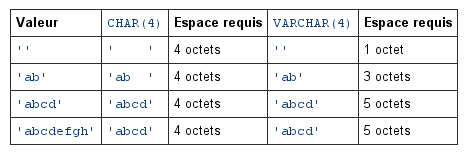
Voyons sans plus tarder un exemple avec une table composée de 2 champs; un champ char(6) qui occupe donc 6 octets puisque les chaînes générées le sont avec des caractères ASCII et un champ varchar(6) qui va occuper 7 octets – un préfixe d’un octet + nos 6 octets de caractères – dans laquelle nous insérons des chaînes de caractères aléatoires et en nombre assez conséquent (100 000 entrées). Ne vous inquiétez pas si cela prend quelques secondes à s’exécuter…
CREATE TABLE test_like (
cha char(6) NOT NULL,
var varchar(6) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- le début de notre proc' stock'
DROP PROCEDURE IF EXISTS insertion;
DELIMITER //
CREATE PROCEDURE insertion()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE (i<=100000) DO
INSERT INTO test_like VALUES
(
SUBSTRING(MD5(RAND()) FROM 1 FOR 6),
SUBSTRING(MD5(RAND()) FROM 1 FOR 6));
SET i=i+1;
END WHILE;
END
//
CALL insertion();
C’est vrai que de prime abord faire
select * from test_like
where cha like 'ee43b9'
ou
select * from test_like
where cha = 'ee43b9'
sur notre champ de type CHAR revient au même, tout comme :
select * from test_like
where var like 'fb7bb8'
produit le même résultat que
select * from test_like
where var = 'fb7bb8'
J’ai lu sur certains forums anglophones que le comportement de = ou like dépendait du type de données de la colonne (CHAR/VARCHAR), c’est peut-être vrai sur certains RDBMS, mais pas avec MySQL, vous en avez la preuve concrète. Le changement est surtout visible lorsque l’on pose un index sur la colonne concernée :
ALTER TABLE test_like ADD INDEX (cha)
Ainsi, voici ce que nous donne un EXPLAIN. Tout d’abord sur le LIKE :
explain select * from test_like where cha like 'ee43b9'
+—-+————-+———–+——-+—————+——+———+——+——+————-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+—-+————-+———–+——-+—————+——+———+——+——+————-+
| 1 | SIMPLE | test_like | range | cha | cha | 18 | NULL | 1 | Using where |
+—-+————-+———–+——-+—————+——+———+——+——+————-+
1 row in set (0.01 sec)
Et ensuite sur le = :
explain select * from test_like where cha = 'ee43b9'
+—-+————-+———–+——+—————+——+———+——-+——+————-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+—-+————-+———–+——+—————+——+———+——-+——+————-+
| 1 | SIMPLE | test_like | ref | cha | cha | 18 | const | 1 | Using where |
+—-+————-+———–+——+—————+——+———+——-+——+————-+
1 row in set (0.01 sec)
Nous obtenons la même chose sur le champ de type VARCHAR après avoir posé un index dessus. Une recherche avec un LIKE sur un champ indexé donne un type = range alors qu’une recherche sur un champ indexé donne avec une égalité stricte un type = ref. Voyons ce que dit la documentation officielle à ce sujet :
ref peut être utilisé pour les colonnes indexées, qui sont comparées avec l’opérateur =.
C’est bien le cas ! Pour le range :
range peut être utilisé lorsqu’une colonne indexée est comparée avec une constante comme =, <>, >, >=, <, <=,IS NULL, <=>, BETWEEN ou IN.
Les exemples de la documentation officielle montrent bien que range peut-être AUSSI utilisé avec un = mais plutôt sur des types de données numériques…
Les tests réalisés sur un serveur MySQL situé sur le réseau local
Pour le champ de type CHAR
CHAR(6) indexé, LIKE sur une valeur existante, bypass du cache de requêtes MySQL :
SELECT SQL_NO_CACHE *
FROM test_like
WHERE cha LIKE 'edd34e'
1 total, Traitement en 0.0103 sec.
CHAR(6) indexé, LIKE sur une valeur inexistante, bypass du cache de requêtes MySQL :
SELECT SQL_NO_CACHE *
FROM test_like
WHERE cha LIKE 'fb7bb8'
MySQL n'a retourné aucune ligne. ( Traitement en 0.0007 sec. )
CHAR(6) indexé, = sur une valeur existante, bypass du cache de requêtes MySQL :
SELECT SQL_NO_CACHE *
FROM test_like
WHERE cha = 'edd34e'
Traitement en 0.0008 sec.
CHAR(6) indexé, = sur une valeur inexistante, bypass du cache de requêtes MySQL :
SELECT SQL_NO_CACHE *
FROM test_like
WHERE cha = 'udd34e'
MySQL n'a retourné aucune ligne. ( Traitement en 0.0006 sec. )
Pour le champ de type VARCHAR
VARCHAR(6) indexé, LIKE sur une valeur existante, bypass du cache de requêtes MySQL :
SELECT SQL_NO_CACHE *
FROM test_like
WHERE var LIKE '64eaee'
1 total, Traitement en 0.0455 sec.
VARCHAR(6) indexé, LIKE sur une valeur inexistante, bypass du cache de requêtes MySQL :
SELECT SQL_NO_CACHE *
FROM test_like
WHERE var LIKE '88eaee'
MySQL n'a retourné aucune ligne. ( Traitement en 0.0659 sec. )
VARCHAR(6) indexé, = sur une valeur existante, bypass du cache de requêtes MySQL :
SELECT SQL_NO_CACHE *
FROM test_like
WHERE var = '6753ec'
1 total, Traitement en 0.0520 sec.
VARCHAR(6) indexé, = sur une valeur inexistante, bypass du cache de requêtes MySQL :
SELECT SQL_NO_CACHE *
FROM test_like
WHERE var = '8888ec'
MySQL n'a retourné aucune ligne. ( Traitement en 0.0513 sec. )
D’après ce petit benchmark très rapide et sans grande prétention :
- sur un VARCHAR, like est un peu plus rapide que =
- sur un CHAR intégralement rempli, = est beaucoup plus rapide que like